ReLU (Rectified Linear Unit) and Leaky ReLU are both types of activation functions used in neural networks.
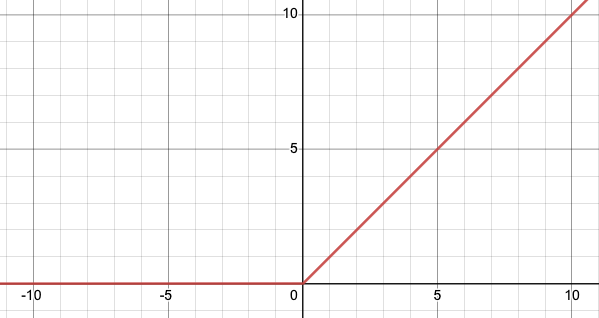
ReLU is defined as f(x) = max(0, x), where x is the input to the function. It sets all negative input values to zero while allowing all non-negative values to pass through unchanged. This can help speed up training and improve the performance of the model because it reduces the number of negative input values that need to be processed by the model.
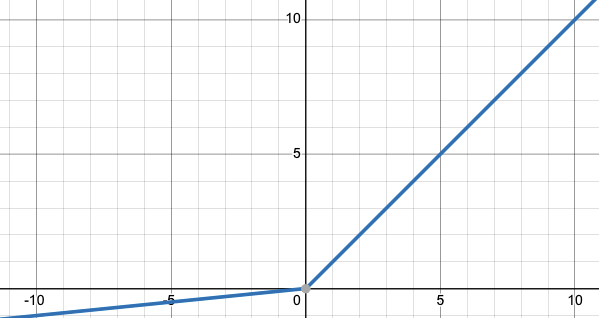
Leaky ReLU is an extension of ReLU that aims to address the problem of “dying ReLUs” in which some neurons in the network never activate because the gradient is zero for all input values less than zero. It can be defined mathematically as f(x) = max(x, kx) where k is usually a small negative slope (of 0.01 or so) for negative input values, rather than being zero as in a standard ReLU.
In practice, LeakyReLU is being used as a generalization of ReLU. This small negative slope helps in avoiding the dying ReLU problem. Also, it helps to train a network faster as the gradients for negative input values will not be zero. A general rule of thumb when choosing between the two would be that, if the problem does not have sparse inputs and the data set is not too small, using Leaky ReLU may result in a more accurate model. Otherwise, if the problem has sparse inputs and/or the data set is small, then using ReLU is a better choice.
It also depends on personal preferences and what the dataset is like. Sometimes leaky ReLU may work better in some cases and sometimes ReLU may be better. It’s important to try out different activation functions and see which one gives the best performance on your dataset.

Leave a comment