In Part 1, we learned how to create the vector database and add documents to a collection. In this tutorial, we will learn how you can query the collection, upsert documents, delete individual documents and also the collection.
Querying
Now you can either peek at the collection, which will return you the first 10 documents in the collection, you can also specify the number of documents to peek at, or you can specify either the metadata or the ID you want to retrieve.
collection.peek(5) # Returns the top 5 documents
collection.get(ids=['pdf_chunk_0', 'pdf_chunk_1']) # Returns the documents corresponding to ids mentioned in the listYou can also query a collection using the where method, where you can specify metadata. For example, in Part 1 we added metadata to each document, where the file name was reasearch_paper. So we can query all documents with the metadata.
collection.get(where={'file_name': 'reasearch_paper'})Another thing you can do is query the most similar documents to an input query. For example, I want to know in the research paper who the authors are, I can get the documents which may contain this information by running –
collection.query(query_texts=["Who are the authors of the paper ?"], n_results=3)Here the query texts are my queries and n_results is the number of similar documents I want for the query. You can specify multiple queries at the same time. In that case, it will return results for each query at the same time.
Upserting
Similar to querying, you can upsert providing the IDs. So for example I want to upsert the data in ID pdf_chunk_0, then I’ll run the following –
collection.upsert(ids=['pdf_chunk_0'], documents=['This is an example of upsertion'])Now if I query the document, I should see the above document text instead of the original document. Note that if you provide an ID which is not present, ChromaDB will consider it as an add operation.
Deleting
Again you can delete individual documents by either specifying the IDs or using the where method. So in case I want to delete pdf_chunk_0, I can run this – collection.delete(ids = ['pdf_chunk_0']) or if I want to delete all documents containing some metadata, I can run this query – collection.delete(where={"file_name": "research_paper"})
You can also delete the entire collection by client.delete_collection('research')
In case you want to reset the client, and you’ve allowed so when creating the persistent client in the setting, you can run client.reset(). Empties and completely resets the database. ⚠️ This is destructive and not reversible.
Let me know In case you want to learn more about ChromaDB, then I’ll create a guide for advanced users.


 , which gives the solution as x = 0. But what if you don’t know this and need to rely on a method which can reach the minimum of a function iteratively. That is what gradient descent does.
, which gives the solution as x = 0. But what if you don’t know this and need to rely on a method which can reach the minimum of a function iteratively. That is what gradient descent does. 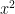 and we start off with an initial value say 7. Then we we will update the value of x as –
and we start off with an initial value say 7. Then we we will update the value of x as – )*x_old*lr
)*x_old*lr