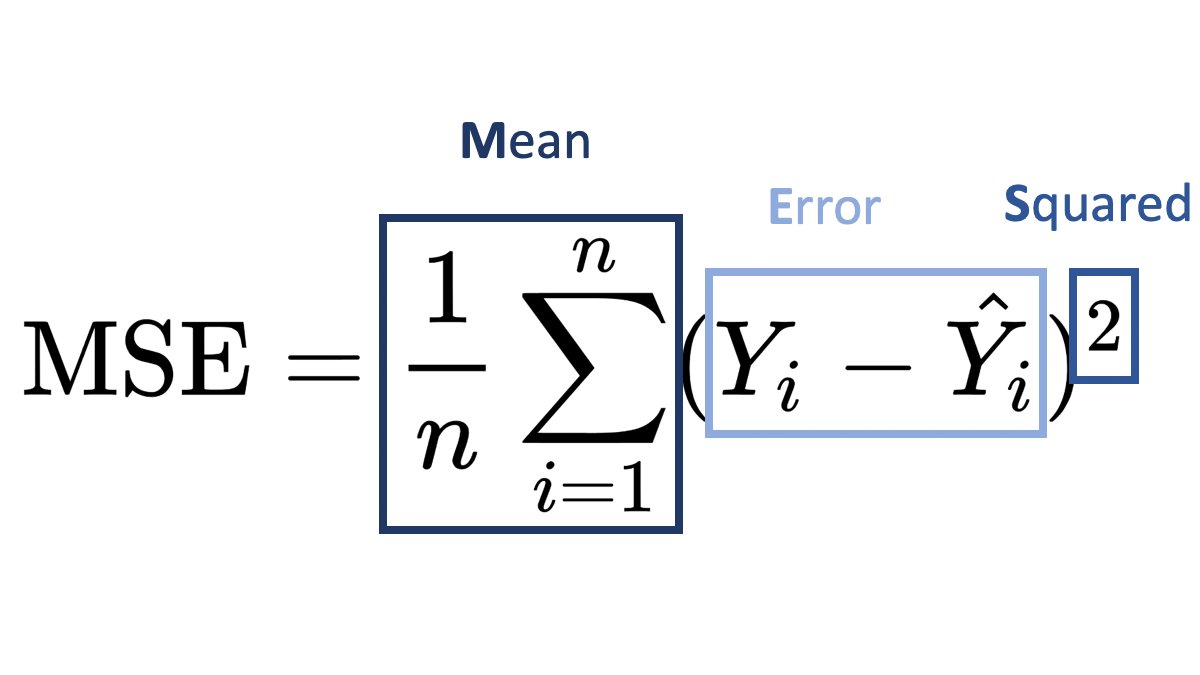
Often after training a ML model, you want to move it to production, sometimes you also want to store certain metadata about the model like its author, version, or other characteristics about it.
The first solution that comes to mind is creating a JSON or Python file within your repository and storing those there, but you can actually store metadata within the model file. I’ll show two examples of how you can do so in xgboost and catboost.
For catboost the code snippet is below, it is pretty straightforward.
from catboost import CatBoostRegressor
# Define your metadata
metadata = {
'author': 'John Doe',
'description': 'CatBoost model for classification',
'version': '1.0',
# Add any other metadata fields as needed
}
# Initialise your model with the added metadata
model = CatBoostRegressor(metadata=metadata)
# Fit the model on your data
model.fit(X,y)
model.save_model('/path/to/model.cbm')
Then you can load the model back using the below snippet and inspect the metadata stored within your model file.
model = CatBoostRegressor()
model.load_model('/path/to/model.cbm')
print(model.get_metadata()['author'])
>>> John Doe
For Xgboost, you can visit this link.

 is the standard deviation of the entire population if available.
is the standard deviation of the entire population if available.