We all know about LogLoss which is the main loss function when it comes to binary classification problems. The formula is given below –

- (N) is the total number of samples.
- (y_i) is the true label of sample (i) (0 or 1).
- (p_i) is the predicted probability of sample (i) belonging to class 1.
Imbalanced Log Loss:
The imbalanced log loss accounts for class imbalance by introducing class weights. It can be defined as:

- (N) is the total number of samples.
- (y_i) is the true label of sample (i) (0 or 1).
- (p_i) is the predicted probability of sample (i) belonging to class 1.
- (w_i) is the weight assigned to sample (i) based on its class label. For example, if class 0 has fewer samples than class 1, (w_i) can be set to the ratio of class 1 samples to class 0 samples.
Here is the python code that you can call to evaluate in Catboost –
class BalancedLogLoss:
def get_final_error(self, error, weight):
return error
def is_max_optimal(self):
return False
def evaluate(self, approxes, target, weight):
y_true = target.astype(int)
y_pred = approxes[0].astype(float)
y_pred = np.clip(y_pred, 1e-15, 1 - 1e-15)
individual_loss = -(y_true * np.log(y_pred) + (1 - y_true) * np.log(1 - y_pred))
class_weights = np.where(y_true == 1, np.sum(y_true == 0) / np.sum(y_true == 1), np.sum(y_true == 1) / np.sum(y_true == 0))
weighted_loss = individual_loss * class_weights
balanced_logloss = np.mean(weighted_loss)
return balanced_logloss, 0.0Advantages of Imbalanced LogLoss –
- Handles Class Imbalance: The imbalanced log loss takes into account the class distribution and assigns appropriate weights to each class. This allows the model to effectively handle imbalanced datasets, where one class may have significantly fewer samples than the other. By assigning higher weights to the minority class, the model focuses more on correctly classifying the minority class, reducing the impact of class imbalance.
- Improves Model Performance: By incorporating class weights in the loss function, the imbalanced log loss guides the model to optimize its predictions specifically for imbalanced datasets. This can lead to improved model performance, as the model becomes more sensitive to the minority class and learns to make better predictions for both classes.
- Flexible Weighting Strategies: The imbalanced log loss allows flexibility in assigning weights to different classes. Various weighting strategies can be used based on the characteristics of the dataset and the specific problem at hand. For example, weights can be inversely proportional to class frequencies or can be set manually based on domain knowledge. This flexibility enables the model to adapt to different levels of class imbalance and prioritize the correct classification of the minority class accordingly.
- Evaluation Metric Consistency: When using the imbalanced log loss as both the training loss and evaluation metric, it ensures consistency in model optimization and evaluation. By optimizing the model to minimize the imbalanced log loss during training, the model’s performance is directly aligned with the evaluation metric, providing a fair assessment of the model’s effectiveness in handling class imbalance.
In conclusion, if you have an imbalanced class problem, you can try this eval metric in your models as well.
.




 and another matrix R of dimension
and another matrix R of dimension  whose columns are representing random directions, the random projection of M is then calculated as
whose columns are representing random directions, the random projection of M is then calculated as 
 .
.
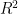 you also calculate the adjusted r2,
you also calculate the adjusted r2,  , which adjusts for the number of variables in the model and penalizes models with an excessive number of variables.
, which adjusts for the number of variables in the model and penalizes models with an excessive number of variables.