
We know that calculating the correlation between numerical variables is very easy, all you have to do is call df.corr().
But how do you calculate the correlation between categorical variables?
If you have two categorical variables then the strength of the relationship can be found by using Chi-Squared Test for independence.
The Chi-square test finds the probability of a Null hypothesis (H0).
Assumption(H0): The two columns are not correlated. H1: The two columns are correlated. Result of Chi-Sq Test: The Probability of H0 being True
We will be using the titanic dataset to calculate the chi-squared test for independence on a couple of categorical variables.

import numpy as np
import pandas as pd
import seaborn as sns
from matplotlib import pyplot as plt
df = sns.load_dataset('titanic')
corr = df[['age', 'fare', 'pclass']].corr()
# Generate a mask for the upper triangle
mask = np.triu(np.ones_like(corr, dtype=bool))
# Set up the matplotlib figure
f, ax = plt.subplots(figsize=(11, 9))
# Generate a custom diverging colormap
cmap = sns.diverging_palette(230, 20, as_cmap=True)
# Draw the heatmap with the mask and correct aspect ratio
sns.heatmap(corr, mask=mask, cmap=cmap, vmax=.3, center=0,
square=True, linewidths=.5, cbar_kws={"shrink": .5})
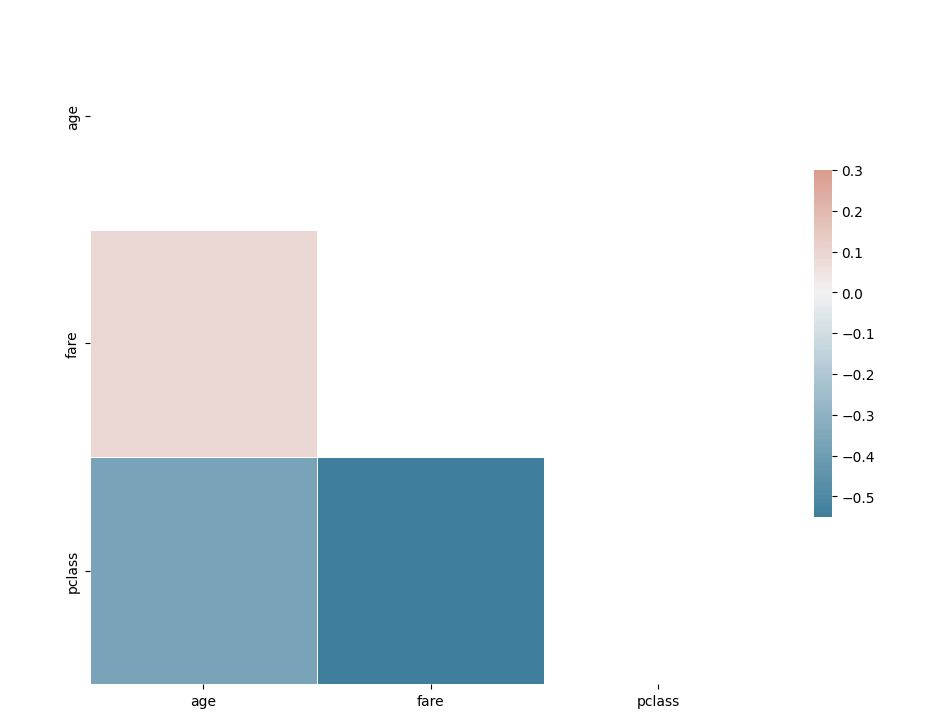
Pretty easy to calculate the correlation among numerical variables.
Lets first calculate first whether the class of the passenger and whether or not they survive have a correlation.
# importing the required function
from scipy.stats import chi2_contingency
cross_tab=pd.crosstab(index=df['class'],columns=df['survived'])
print(cross_tab)

chi_sq_result = chi2_contingency(cross_tab,)
p, x = chi_sq_result[1], "reject" if chi_sq_result[1] < 0.05 else "accept"
print(f"The p-value is {chi_sq_result[1]} and hence we {x} the null Hpothesis with {chi_sq_result[2]} degrees of freedom")
The p-value is 4.549251711298793e-23 and hence we reject the null Hpothesis with 2 degrees of freedom
Similarly, we can calculate whether two categorical variables are correlated amongst other variables as well.
Hopefully, this clears up how you can calculate whether two categorical variables are correlated or not in python. In case you have any questions please feel free to ask them in the comments.



 where the k-factor determines how the rating reacts to new results. If the value is set too high the ratings will jump around too much and if set too low it will take a long time to recognize greatness.
where the k-factor determines how the rating reacts to new results. If the value is set too high the ratings will jump around too much and if set too low it will take a long time to recognize greatness.





 time complexity.
time complexity.