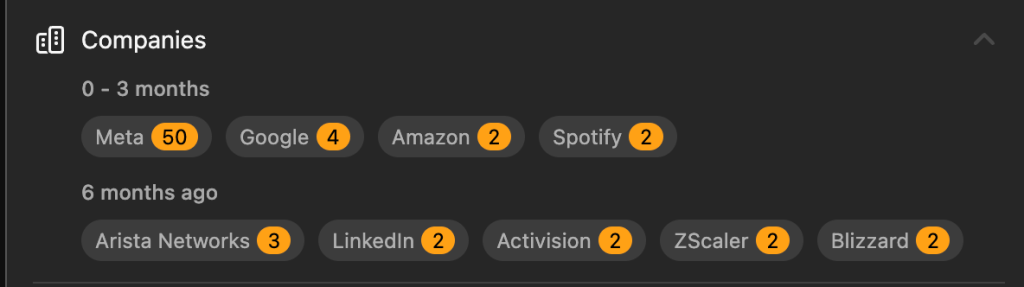
This is one of the most asked questions by Meta in the past 3 months.

Given a string s of '(' , ')' and lowercase English characters.
Your task is to remove the minimum number of parentheses ( '(' or ')', in any positions ) so that the resulting parentheses string is valid and return any valid string.
Formally, a parentheses string is valid if and only if:
- It is the empty string, contains only lowercase characters, or
- It can be written as
AB(Aconcatenated withB), whereAandBare valid strings, or - It can be written as
(A), whereAis a valid string.
Example 1:
Input: s = "lee(t(c)o)de)"
Output: "lee(t(c)o)de"
Explanation: "lee(t(co)de)" , "lee(t(c)ode)" would also be accepted.
The way to solve the problem is by using a combination of stack and a set.
You iterate through the string and check if the parentheses is valid with the help of a stack, as you do in the easy question Valid Parentheses. If you come across an invalid one, then you add the index to your set which tracks which indices to remove.
In the example lee(t(c)o)de) , we will initialise our stack to be empty and iterate through the array. Once we encounter a parenthesis, we check if its a closing or opening one. So we go through l,e,e, and we now have (, so we add the index to the stack. Our stack becomes [3], we continue and keep adding to the stack if it’s an open, otherwise we pop from the stack.
So our stack is [3,5] when we are at lee(t(c, now we see two closing brackets, so we pop twice from the stack. At the end of the string we see that we’ve a closing bracket and our stack is empty, so we will add this index to our set.
We then iterate through our string again and build our return string, skipping over characters which are part of our remove set.
The solution will work, but we’ve overlooked an edge case when our stack is non-empty, in that case all we’ve to do it do a union of the set and stack indices and keep track of it rather than only the set.
Here is the solution in python.
class Solution:
def minRemoveToMakeValid(self, s: str) -> str:
stack = []
remove_set = set()
for i,char in enumerate(s):
if char not in "()":
continue
elif char == "(":
stack.append(i)
elif not stack:
remove_set.add(i)
else:
stack.pop()
indices_remove = remove_set.union(set(stack))
output = []
for i,char in enumerate(s):
if i in indices_remove:
continue
else:
output.append(char)
return "".join(output)
The time complexity will be O(N) as we are doing a two pass solution and the space complexity is O(N) as in the worst case we might have the entire string as invalid.
Let me know in the comments if you want me to cover other leetcode problems. Thanks for reading.



 time complexity.
time complexity.