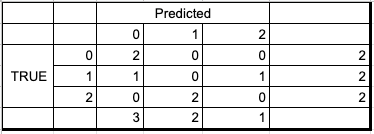
I was going through Kaggle competitions when this competition caught my eye, especially the evaluation metric for it. Now the usual metrics for forecasting or regression problems are either 

SMAPE (Symmetric Mean Absolute Percentage Error) is a metric that is used to evaluate the accuracy of a forecast model. It is calculated as the average of the absolute percentage differences between the forecasted and actual values, with the percentage computed using the actual value as the base. Mathematically, it can be expressed as:

So when to use which metric ?
- RMSE – When you want to penalize large outlier errors in your prediction model, RMSE is the metric of choice as it penalizes large errors more than smaller ones.
- MAPE – All errors have to be treated equally, so in those cases MAPE makes sense to use
- sMAPE – is typically used when the forecasted values and the actual values are both positive, and when the forecasts and actuals are of similar magnitudes. It is symmetric in that it treats over-forecasting and under-forecasting the same.
It is important to note that in both MAPE and sMAPE, values of 0 are not allowed for both actual and forecast values as it would result in division by zero error.