I often find people who are just starting out using pandas struggling to grasp when they should be using axis=0 and axis=1. While I go into a lot more detail with examples in the Youtube video above, you should keep this in mind.
When you use axis=0, pandas only looks at the value being passed, but when you use axis=1, by default it assumes a pandas Series being passed, so it looks for the index. So when you write a function which references multiple columns and use apply, use axis=1 and remember that it considers each row as a pandas Series, with the column names in the index.
So today I was participating in this Kaggle competition and the data had too many categorical variables. One way to build a model with too many categorical variables is to use a model like Catboost and let it deal with encoding categorical variables. But I wanted to ensemble my results with an Xgboost model, so I had to encode them. Using the weight of evidence encoding, I got a solution which was a top 10 solution when submitted. I have made the notebook public, you can go here and see it.
So what is weight of evidence ?
To put it simply –
I’ve gone through an example explaining the weight of evidence in the youtube video below.
In this post, we will go over the complete decision tree theory and also build a very basic decision tree using information gain from scratch.
The below jupyter notebook as a Github Gist shows all the explanations and steps, including how to calculate Gini, Information gain and building a decision tree using the information gain you calculate.
You can also watch the video explainer here on youtube.
While the questions that you may be asked in a data science interview can vary a lot depending on the job description and the skillsets the organisation is looking for, there are a few questions that are often asked and as a candidate, you should know the answer to these.
Here in this post I’ll try to cover 10 such questions that you should know –
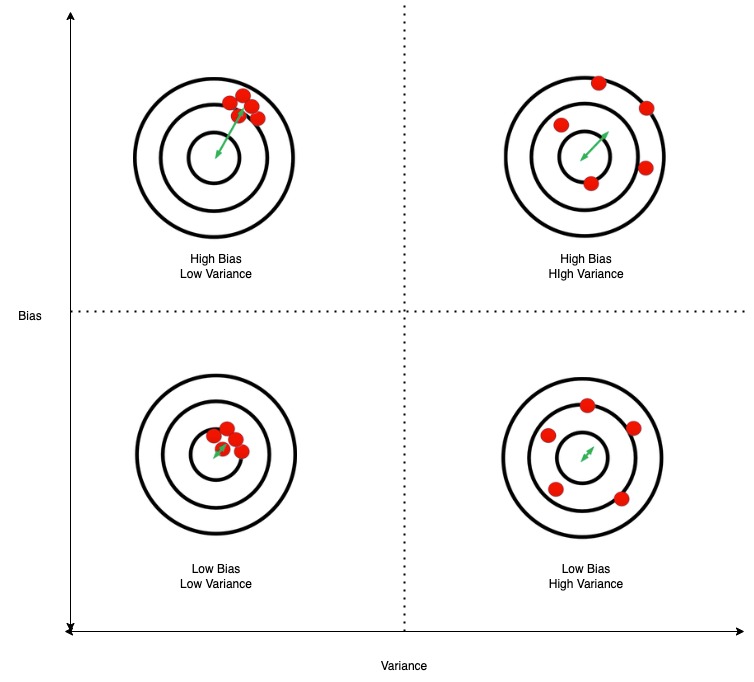
1. What is Bias-Variance Trade-off?
Bias in very simple terms is the error of your ML model. Variance is the difference in the evaluation metric in the train set and the test set that your model achieves. With any machine learning model, you try to reduce both bias and variance. The bias-variance trade-off is as you reduce bias, variance usually increases. So you try to select the ML model which has the lowest bias and variance. The below diagram should explain bias and variance.
2. In multiple linear regression if you keep adding dependent variables, the coefficient of determination (R-squared value) keeps going up, how do you then measure whether the model is improving or not?
In case of multiple linear regression, in addition to the you also calculate the adjusted r2, , which adjusts for the number of variables in the model and penalizes models with an excessive number of variables.
You should stop adding dependent variables when the adjusted r2 values starts to worsen
3. How does Random Forest reduce variance?
The main idea behind the Random Forest algorithm is to use low-bias decision trees and aggregate their results to reduce variance. Since each tree is grown from a bagged sample and also the features are bagged, meaning that each tree is grown from a different subset of features, thus the trees are not correlated and hence their combined results lead to lower variance than a single decision tree with low bias and high variance.
4. What are the support vectors in support vector machine (SVM)?
The support vectors are the data points that are used to define the decision boundary, or hyperplane, in an SVM. They are the key data points that determine the position of the decision boundary, and any change in these support vectors will result in a change in the decision boundary.
5. What is cross-validation and how is it used to evaluate a model’s performance?
Cross-validation involves dividing the available data into two sets: a training set and a validation set. The model is trained on the training set, and its performance is evaluated on the validation set. This process is repeated multiple times with different partitions of the data, and the performance measure is averaged across all iterations. This gives a more robust estimation of the model’s performance than a single train test split can do.
There are different types of cross-validation methods like k-fold cross-validation, in which the data is divided into k-folds, and the model is trained on k-1 folds and tested on the remaining fold. This process is repeated k times, and the performance measure is averaged across all iterations. Another one is Leave one out Cross-validation(LOOCV), in this method we use n-1 observations for training and the last one for testing. There is also a time-series cross-validation where the model is trained till time t and tested for a time after t. The window of training time keeps expanding after each iteration, it is also called expanding window cross-validation for time series.
I’ll be posting more Data Science questions on the blog so keep following for updates.
I was going through Kaggle competitions when this competition caught my eye, especially the evaluation metric for it. Now the usual metrics for forecasting or regression problems are either or , but sMAPE is different.
SMAPE (Symmetric Mean Absolute Percentage Error) is a metric that is used to evaluate the accuracy of a forecast model. It is calculated as the average of the absolute percentage differences between the forecasted and actual values, with the percentage computed using the actual value as the base. Mathematically, it can be expressed as:
So when to use which metric ?
RMSE – When you want to penalize large outlier errors in your prediction model, RMSE is the metric of choice as it penalizes large errors more than smaller ones.
MAPE – All errors have to be treated equally, so in those cases MAPE makes sense to use
sMAPE – is typically used when the forecasted values and the actual values are both positive, and when the forecasts and actuals are of similar magnitudes. It is symmetric in that it treats over-forecasting and under-forecasting the same.
It is important to note that in both MAPE and sMAPE, values of 0 are not allowed for both actual and forecast values as it would result in division by zero error.
In this post, I’ll go over macro and micro averages, namely precision, and recall.
What is macro and micro averages ?
A macro takes the measurement independently of each class and then takes the average, thus giving equal weight to each class whereas a micro will take the class imbalances into account when computing the average.
When to use macro vs micro averages ?
If you suspect class imbalances to be there, then micro average should be preferred to macro.
Whenever we come across an imbalanced class problem, the metric to measure is often F1 score and not accuracy. A quick reminder that the F1 score is the harmonic mean of precision and recall.
Precision is how accurate is your ML model in its predictions.
Recall is a measure of the model’s ability to correctly identify the positive class.
So the F1 score is a balanced measure of both recall and precision. But what if you want to prioritize reducing false positives or reducing false negatives, there comes F-beta. It’s a generalized metric, where a parameter beta is introduced to generalize the F-score.
This enables one to choose an appropriate beta value to tune for the task at hand. If you want to minimize false positives, you want to increase the weight of precisions, so you should choose a value of beta less than 1, typically 0.5 is chosen and is called F0.5 score.
Similarly, if you want to increase the importance of recall and reduce false negatives, you should choose a value of beta greater than 1, typically 2 is selected and is called F2 score.
In a nutshell, you should optimize F2 score to reduce false negatives and F0.5 score to reduce false positives.
Decision trees are the building blocks of most ML models. So often questions regarding Decision Trees are asked in data science interviews. In this post, I’ll try to cover some questions which are asked during data science interviews but often catch people by surprise.
Are Decision Trees Parametric or non-parametric models ?
Decision Trees are non-parametric models. Linear Regression and Logistic regression are examples of parametric models
Why is Gini Index preferred way of growing decision trees than Entropy in Machine Learning libraries ?
The calculation for Gini Index is computationally more effecient than that for Entropy.
It’s because of this reason that it is the preferred way
How are continouis variables handled as predictor variables in decision trees ?
Continuous or numerical variables are binned and then used for splitting a node in Decision tree
What is optimised in case the target is a continuous variable or when the task is Regression ?
Variance reduction is used to choose the best split when the target is continuous.
How do decision trees handle multiple classes or in other words does multi-class classification ?
The split is done on Information gain like in case of binary classifier using Gini or Entropy. In the leaf where no further splits are possible, the class having the highest probability is the predicted class. You can even return the probability as well.
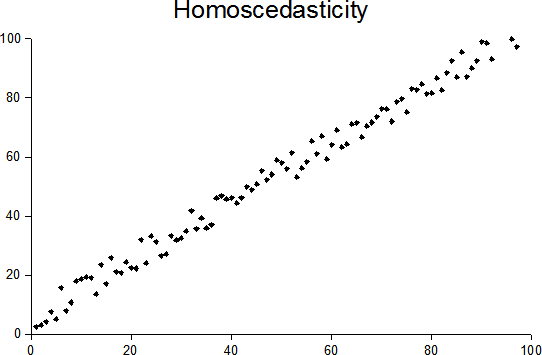
Once your linear regression model is trained, you should always plot your residuals (y – ŷ) whether the errors are homoscedastic or heteroscedastic. What do we mean by these terms? It means that there should not be any pattern in residuals and they should be uniformly distributed, or in other words, there should not be any variance in the residuals. Homoscedasticity is one of the assumptions of linear regression, so it is often important to check for it.
source: Wikipedia
source: Wikipedia
In the above figures, you can clearly see that the residuals have a clear pattern in the heteroscedastic image. In that scenario, you cannot rely on the regression analysis.
How to test for heteroscedasticity?
There are many ways to test for heteroscedasticity, I’ll list a. few ways here –
Visual Test – Just look at the residual plot and you’ll often see whether the residuals have any variance or not, not very accurate but often works.
Bartlett test
Breusch Pagan test
Goldfeld Quandt test
Glesjer test
Test based on Spearman’s rank correlation coefficient
White test
Ramsey test
Harvey Phillips test
Szroeter test
Peak test (nonparametric) test
All these tests in one way or another try to reject the null hypothesis H0 : variance is constant and the alternative hypothesis is that Ha : variance is not constant. You can go into detail about the tests here.
Variance Inflation Factor (VIF) determines the multicollinearity amongst the independent variables (predictors). Multicollinearity is when there is a high correlation between your predictor variables, usually 0.8 or higher. This can adversely affect your regression analysis.
How is it calculated?
VIF of a predictor variable is calculated by regressing it against all other predictor variables. This gives the R2 value which can be plugged into this formula
This will give the VIF value of a predictor.
VIF = 1, not correlated
VIF < 5, slightly correlated
VIF > 5, highly correlated
These values are just guidelines and how high acceptable VIF values are depends on the problem statement.
If you don’t want to use VIF and have very few predictor variables, one can plot a correlation matrix and remove the highly correlated variables.
You might also wonder why do we calculate the p-value of predictor variables in Linear regression. Find out why here.

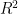 you also calculate the adjusted r2,
you also calculate the adjusted r2,  , which adjusts for the number of variables in the model and penalizes models with an excessive number of variables.
, which adjusts for the number of variables in the model and penalizes models with an excessive number of variables.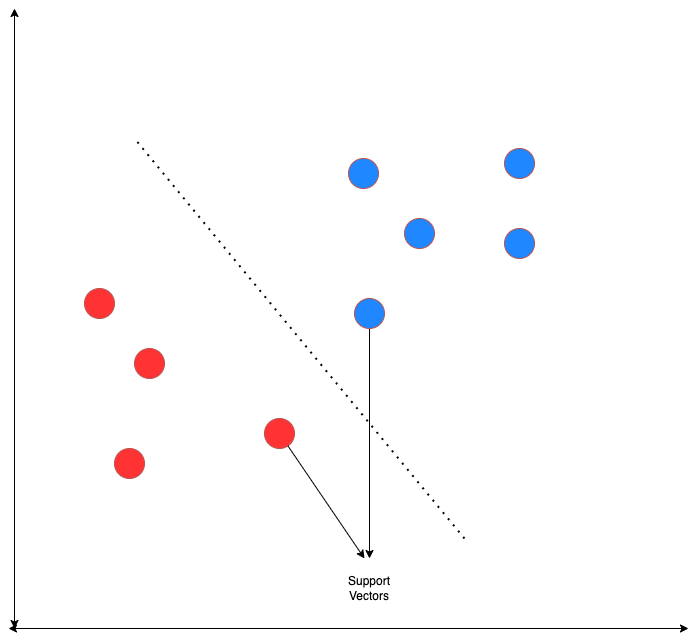
 or
or  , but sMAPE is different.
, but sMAPE is different.