In this post, I’ll go over macro and micro averages, namely precision, and recall.
What is macro and micro averages ?
A macro takes the measurement independently of each class and then takes the average, thus giving equal weight to each class whereas a micro will take the class imbalances into account when computing the average.
When to use macro vs micro averages ?
If you suspect class imbalances to be there, then micro average should be preferred to macro.
How are they different ?
Let’s take an example scenario from here.
from sklearn.metrics import precision_score
y_true = [0, 1, 2, 0, 1, 2]
y_pred = [0, 2, 1, 0, 0, 1]
precision_score(y_true, y_pred, average='macro')
0.22...
precision_score(y_true, y_pred, average='micro')
0.33...
You can see that the precision score is different for macro calculation vs micro calculation.
Breaking down the calculation here in the confusion matrix
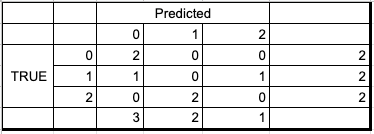
A quick recap the the precision formula is for binary classification problem –

For multi-class the micro and macro formula can be written as –


So in the above example, the micro precision is

Similarly the Precision for each class individually is
P(0) = 2/3 = 0.66, P(1) = 0, P(2) = 0
So macro precision is

In this way the micro vs macro averages differ. Hope this article cleared your problems on macro vs micro averages in ML metrics.
