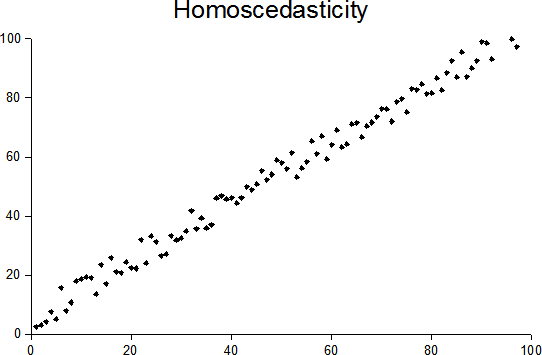
You might be asked that why often in neural networks, tanh is considered to be a better activation function than sigmoid.

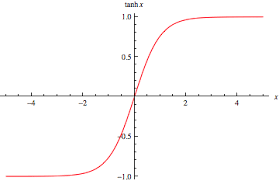
Andrew NG also mentions in his deep learning specialization course that tanh is almost always a better activation function than sigmoid. So why is that the case?
There are a few reasons why the hyperbolic tangent (tanh) function is often considered to be a better activation function than the sigmoid function:
- The output of the tanh function is centered around zero, which means that the negative inputs will be mapped to negative values and the positive inputs will be mapped to positive values. This makes the learning process of the network more stable.
- The tanh function has a derivative that is well-behaved, meaning that it is relatively easy to compute and the gradient is relatively stable.
- The sigmoid function, on the other hand, maps all inputs to values between 0 and 1. This can cause the network to become saturated, and the gradients can become very small, making the network difficult to train.
- Another reason is that the range of the tanh function is [-1,1], while the range of the sigmoid function is [0,1], which makes the model output values more similar to the standard normal distribution. It will be less likely to saturate and more likely to have a good gradient flow, leading to faster convergence.
- Another advantage is that the tanh function is differentiable at all points. In contrast, the sigmoid function has a kink at 0, which may cause issues when computing gradients during back-propagation, and other optimization methods.
All that being said, whether to use sigmoid or tanh depends on the specific problem and context, and it’s not always the case that one is clearly better than the other.